众所周知,golang的goroutine是go并发编程的基础知识,我们只需要使用简单go func()就可以开启一个go协程,然后调度器会管理go协程分配相应的P和M,执行相应的业务逻辑,而且开启一个goroutine代价很小,只会占用2k的栈空间。但是协程也不是随意想开多少就多少,过多的goroutine不仅会影响调度器的执行时间,也会造成内存的快速增长。
今天给大家分享一个github上有1w star的协程池库ants。“ants是一个高性能的 goroutine 池,实现了对大规模 goroutine 的调度管理、goroutine 复用,允许使用者在开发并发程序的时候限制 goroutine 数量,复用资源,达到更高效执行任务的效果。从benchmark的结果来看,使用ants的吞吐性能相较于原生 goroutine 可以保持在 2-6 倍的性能压制,而内存消耗则可以达到 10-20 倍的节省优势”(来自仓库描述),具体的细节可以看git仓库。
设计理念#
ants的设计理念是使用N个work goroutine 完成M个task的执行。控制goroutine的数量。就像仓库中的Activity Diagrams描述的那样。但是这样的设计也会有一些弊端,我们后面再聊(图片来自原github仓库)。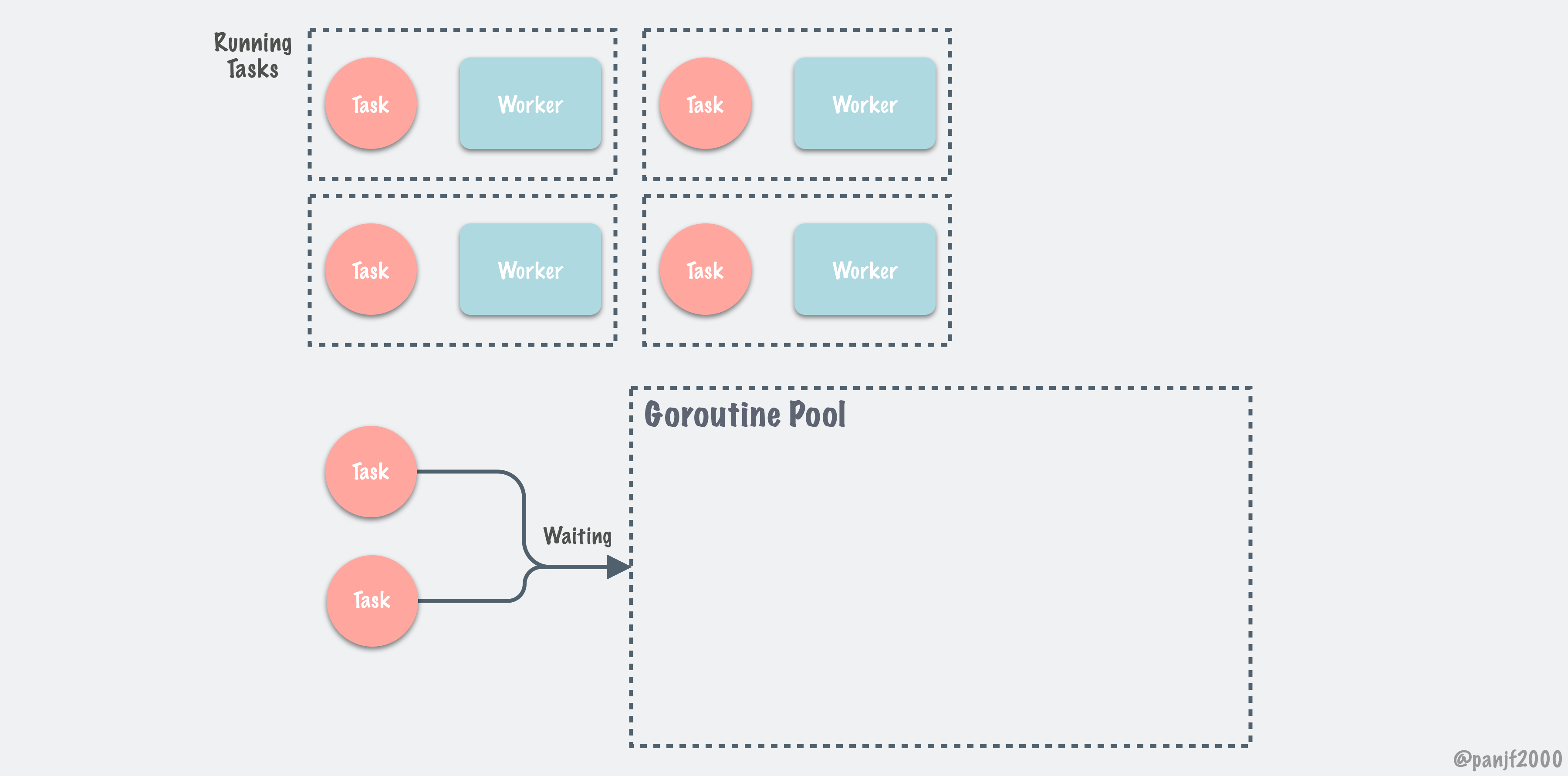
目录结构#
ants的代码并不多,除了test外总共也只有十多个文件,而且代码行数也不多,下面是比较重要的几个文件:
- ants.go
- ants.go 封装了外部调用的能力,它会初始化一个无 goroutine 限制的defaultAntsPool对象,提供了任务提交,获取运行协程数量,获取容量等能力。
- pool.go
- pool.go 实现协程池需要的能力。协程池的定义,任务提交,分配协程等逻辑实现,都在这文件中,ants中的defaultAntsPool调用这个文件中的实现。
- pool_func.go
- pool_func.go 和pool.go做的事情差不多,区别在于pool.go可以执行不同的协程任务,pool_func.go 执行的是相同的任务,但是可以传不同的参数。使用场景不同。
- work.go
- work.go 完成具体任务的执行goWork,实例化了work_queue.go中worker interface的实现。和pool.go关联。
- work_func.go
- work_func.go 和work.go的做了同样的事情,它和pool_func.go关联。
- worker_queue.go
- worker_queue.go worker_queue是管理worker执行的队列,定义了worker 和worker queue需要实现的能力。
- worker_loop_queue.go
- worker_loop_queue.go 用队列的形式实现对woker队列的管理。
- worker_stack.go
- worker_stack.go 以栈的形式实现worker队列管理
- options.go
这些就是ants的主要文件,他们之间的关系很简单,workerQueue interface定义了worker队列的能力,有ring queue和stack两种实现。woker interface定义了work的能力,有work和work_func两种实现。协程池也就有对应pool和pool_func两种实现。
源码解析#
ants的代码并不复杂,但是有很多细节,它实现了两种能力的协程池,pool是可以执行不同任务的协程池,poolWithFunc只能执行相同的任务,但是参数可以不同。对应此两种能力,所以有了goWorker和goWokerWithFunc两种worker。我们先介绍pool相关源码(pool关联work.go中的goWorker),大家可以对照阅读poolWithFunc的代码。首先我们先从example入手:(一般开源的代码都会有example文件,我们学习之前可以先从这些示例入手,然后针对感兴趣的模块逐层深入,这样效率会高点)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
//https://github.com/panjf2000/ants/blob/dev/examples/main.go
package main
import (
"fmt"
"sync"
"sync/atomic"
"time"
"github.com/panjf2000/ants/v2"
)
var sum int32
func myFunc(i interface{}) {
n := i.(int32)
atomic.AddInt32(&sum, n)
fmt.Printf("run with %d\n", n)
}
func demoFunc() {
time.Sleep(10 * time.Millisecond)
fmt.Println("Hello World!")
}
func main() {
defer ants.Release()
runTimes := 1000
// Use the common pool.
var wg sync.WaitGroup
syncCalculateSum := func() {
demoFunc()
wg.Done()
}
for i := 0; i < runTimes; i++ {
wg.Add(1)
_ = ants.Submit(syncCalculateSum)
}
wg.Wait()
fmt.Printf("running goroutines: %d\n", ants.Running())
fmt.Printf("finish all tasks.\n")
// Use the pool with a method,
// set 10 to the capacity of goroutine pool and 1 second for expired duration.
p, _ := ants.NewPoolWithFunc(10, func(i interface{}) {
myFunc(i)
wg.Done()
})
defer p.Release()
// Submit tasks one by one.
for i := 0; i < runTimes; i++ {
wg.Add(1)
_ = p.Invoke(int32(i))
}
wg.Wait()
fmt.Printf("running goroutines: %d\n", p.Running())
fmt.Printf("finish all tasks, result is %d\n", sum)
if sum != 499500 {
panic("the final result is wrong!!!")
}
}
|
测试代码介绍了pool和poolWithFunc的使用。syncCalculateSum函数就是我们需要执行的任务,ants.Submit(syncCalculateSum)将任务提交到pool中,然后会分配给work去执行。那么我们去看看Submit具体实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
|
//首先先了解下goWorker的定义
//https://github.com/panjf2000/ants/blob/dev/work.go
type goWorker struct {
// 协程池对象,其实多个goWorker共享的是一个pool对象,在创建worker是传的同一个p,下面代码会讲。
pool *Pool
// 接受任务的有缓冲的chan
task chan func()
// 上次使用时间,主要是清理worker时使用
lastUsed time.Time
}
//https://github.com/panjf2000/ants/blob/dev/pool.go
type Pool struct {
// 协程池的容量,负数代表无限制
capacity int32
//当前在运行的worker数量
running int32
//保护从队列中读写worker
lock sync.Locker
// workers队列,这个队列有stack和ring queue两种实现
workers workerQueue
//协程池状态
state int32
//自旋锁,等待获取空闲的worker
cond *sync.Cond
// workerCache 使用对象池,加快了在 function:retrieveWorker 中获取可用 Worker 的速度。
workerCache sync.Pool
// 阻塞在cond上的任务数量
waiting int32
//清理等待时间过长的worker
purgeDone int32
stopPurge context.CancelFunc
//更新worker的使用时间,也是用于清理
ticktockDone int32
stopTicktock context.CancelFunc
//使用时间
now atomic.Value
//配置信息
options *Options
}
//https://github.com/panjf2000/ants/blob/dev/pool.go
func (p *Pool) Submit(task func()) error {
//判断协程池是否关闭
if p.IsClosed() {
return ErrPoolClosed
}
//检索出一个可用的work,然后将任务交给work去执行
if w := p.retrieveWorker(); w != nil {
w.inputFunc(task)
return nil
}
return ErrPoolOverload
//https://github.com/panjf2000/ants/blob/dev/pool.go
func (p *Pool) retrieveWorker() (w worker) {
//从缓存的对象池中获取一个worker,启动worker接受任务,这里可能会new一个,也可能复用
spawnWorker := func() {
w = p.workerCache.Get().(*goWorker)
w.run()
}
//加锁保护worker的获取
p.lock.Lock()
w = p.workers.detach()
if w != nil {
//如果成功获取一个worker,直接返回
p.lock.Unlock()
} else if capacity := p.Cap(); capacity == -1 || capacity > p.Running() {
//如果初始化是未限制worker的数量,或者当前在运行的worker数量还没到达限制。就调用spawnWorker获取一个
p.lock.Unlock()
spawnWorker()
} else {
//否则证明worker已经使用完了。如果用户设置了不阻塞,就直接返回nil,返回错误给用户
if p.options.Nonblocking {
p.lock.Unlock()
return
}
retry:
//等待空闲的worker释放,如果等待的任务超出限制,直接返回
if p.options.MaxBlockingTasks != 0 && p.Waiting() >= p.options.MaxBlockingTasks {
p.lock.Unlock()
return
}
//cond是实现的指数退避的自旋锁。自旋等待worker释放
p.addWaiting(1)
p.cond.Wait()
p.addWaiting(-1)
//有worker可用或者是pool关闭了,关闭直接返回
if p.IsClosed() {
p.lock.Unlock()
return
}
//work可能被其他等待的任务获取了,如果还未到达容量上限,就从对象池拿一个
//否则重试继续获取
if w = p.workers.detach(); w == nil {
if p.Free() > 0 {
p.lock.Unlock()
spawnWorker()
return
}
goto retry
}
p.lock.Unlock()
}
//成功获取,返回
return
}
//https://github.com/panjf2000/ants/blob/dev/worker.go
func (w *goWorker) inputFunc(fn func()) {
//将任务丢给chan,会有worker去执行
w.task <- fn
}
func (w *goWorker) run() {
w.pool.addRunning(1)
go func() {
//PanicHandler可以设置回调函数,gowoker panic的时候可以做些措施
defer func() {
w.pool.addRunning(-1)
w.pool.workerCache.Put(w)
if p := recover(); p != nil {
if ph := w.pool.options.PanicHandler; ph != nil {
ph(p)
} else {
w.pool.options.Logger.Printf("worker exits from panic: %v\n%s\n", p, debug.Stack())
}
}
// Call Signal() here in case there are goroutines waiting for available workers.
w.pool.cond.Signal()
}()
//每一个goworker都会启动一个协程从chan中读取任务执行,执行完成后将尝试将worker放到pool的队列中。
//如果放入失败,证明协程池中可运行协程数已满 or 当前协程池已经关闭,退出当前goroutine,将goworker放到缓存中。
//如果成功的话,证明当前协程池没满也没关闭,那这个协程就会阻塞在task chan上读取任务,此时这个协程是没有退出的
//goworker对象进入worker队列,等待新任务调度,有新的任务来时,等调度到goworker,然后将任务写入task chan
for f := range w.task {
if f == nil {
return
}
f()
if ok := w.pool.revertWorker(w); !ok {
return
}
}
}()
}
//尝试将goworker放到woker队列中管理
func (p *Pool) revertWorker(worker *goWorker) bool {
//如果池子中运行的worker已经大于最大容量,或者池子已经关闭。返回放入失败
if capacity := p.Cap(); (capacity > 0 && p.Running() > capacity) || p.IsClosed() {
//这里的broadcast我查了资料,没有找到具体的原因,为什么放入失败需要唤醒所有等待的协程。
//我个人的理解是,唤醒retrieveWorker中所有阻塞在p.cond.wait()的协程,函数中会在retry时重新执行
//等待执行的任务是否超过用户设置的MaxBlockingTasks的逻辑。
p.cond.Broadcast()
return false
}
//更新此worker使用时间
worker.lastUsed = p.nowTime()
p.lock.Lock()
// 这里为了避免内存泄漏,二次检查池的状态。具体泄漏场景大家可以看看下面的issue
// Issue: https://github.com/panjf2000/ants/issues/113
if p.IsClosed() {
p.lock.Unlock()
return false
}
//调用worker queue的方法,将worker放入队列管理
if err := p.workers.insert(worker); err != nil {
p.lock.Unlock()
return false
}
//通知所有阻塞在'retrieveWorker()' 方法的协程,有新的worker可用
p.cond.Signal()
p.lock.Unlock()
return true
}
|
整个流程比较简单,调用submit函数提交自定义的任务给协程池,submit调用retrieveWorker获取一个可用的worker,然后在调用inputFunc函数将任务交给这个worker去执行。有几个点需要注意下,workerCache使用了对象池,缓存了goworker对象,从池中Get时,可能会new一个woker(程序刚启动时,还未到达cap限制),也可能会读取使用过的gowoker。还有就是使用了自旋锁sync.Cond等待可用的worker。还有个比较重要的是goworker的run函数,每一个goworker都会启动一个协程从chan中读取任务来执行。每次执行一个任务,都会尝试将此worker重新放入pool的队列中,等待再次调度。如果放入失败,就会放到workerCache对象池,最大程度复用对象。
上面就是整个worker调用和分配的的流程,整体逻辑不是很复杂,但是有很多细节需要注意。下面顺着上面的逻辑,我们介绍下worker_queue
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
//https://github.com/panjf2000/ants/blob/dev/worker_queue.go
type worker interface {
run()
finish()
lastUsedTime() time.Time
inputFunc(func())
inputParam(interface{})
}
type workerQueue interface {
len() int
isEmpty() bool
insert(worker) error
detach() worker
refresh(duration time.Duration) []worker
reset()
}
type queueType int
const (
queueTypeStack queueType = 1 << iota
queueTypeLoopQueue
)
func newWorkerQueue(qType queueType, size int) workerQueue {
switch qType {
case queueTypeStack:
return newWorkerStack(size)
case queueTypeLoopQueue:
return newWorkerLoopQueue(size)
default:
return newWorkerStack(size)
}
|
Pool对象中有workers workerQueue对象,workerQueue管理所有的worker,根据newWorkerQueue方法,我们可以发现workerQueue有两种实现,loopQueue实现了ring queue,底层是slice数组加一些头尾标识来实现,会预先分配slice的大小。stack底层也是slice,默认大小是0,插入worker时,底层自动扩容。除了不同的管理队列实现外。也定义worker和queue需要的一些能力。如果可以的话,我们也可以实现一个queue用来管理worker。
下面我们介绍下初始化pool时的逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
//https://github.com/panjf2000/ants/blob/dev/pool.go
func NewPool(size int, options ...Option) (*Pool, error) {
//协程池没有限制大小
if size <= 0 {
size = -1
}
opts := loadOptions(options...)
//配置是否需要清理worker的功能
if !opts.DisablePurge {
if expiry := opts.ExpiryDuration; expiry < 0 {
return nil, ErrInvalidPoolExpiry
} else if expiry == 0 {
opts.ExpiryDuration = DefaultCleanIntervalTime
}
}
//用户可以自定义logger
if opts.Logger == nil {
opts.Logger = defaultLogger
}
//初始化一个pool结构p,然后创建worker的时候会传入这个p,所以所有的worker都是公用一个p,一个协程池的。
//具体看下workerCache.New方法就可以明白。
//task chan是有缓冲还是无缓冲取决于GOMAXPROCS,具体下面会解释
p := &Pool{
capacity: int32(size),
lock: syncx.NewSpinLock(),
options: opts,
}
p.workerCache.New = func() interface{} {
return &goWorker{
pool: p,
task: make(chan func(), workerChanCap),
}
}
//这里是决定管理worker的队列使用ring queue还是stack。取决是否需要预分配
if p.options.PreAlloc {
if size == -1 {
return nil, ErrInvalidPreAllocSize
}
p.workers = newWorkerQueue(queueTypeLoopQueue, size)
} else {
p.workers = newWorkerQueue(queueTypeStack, 0)
}
//自己实现了个自旋锁,将这个锁作为cond条件变量的关联到这个锁
p.cond = sync.NewCond(p.lock)
//清理程序和更新used time的定时任务
p.goPurge()
p.goTicktock()
return p, nil
}
//workerChanCap的容量取决于核的数量,单核时,我们设置chan为无缓冲,这样的话协程就会立刻从sender转化到receiver,提高程序性能。
//多核时,设置有缓冲的chan,避免接收方接受的速率影响到发送方
workerChanCap = func() int {
// Use blocking channel if GOMAXPROCS=1.
// This switches context from sender to receiver immediately,
// which results in higher performance (under go1.5 at least).
if runtime.GOMAXPROCS(0) == 1 {
return 0
}
// Use non-blocking workerChan if GOMAXPROCS>1,
// since otherwise the sender might be dragged down if the receiver is CPU-bound.
return 1
}()
|
初始化pool的函数中,我们可以配置是否使用purge功能清理woker,是否要自定义logger,是否要预分配workqueue等。比较重要的点就是使用对象池加速worker的分配,共用一个协程池对象p。根据是否预先分配,实现两种work queue,这些都是提升性能的关键点。还有就是自己实现了个自旋锁syncx.NewSpinLock(),加锁时会自旋尝试多次获取。
扩展阅读#